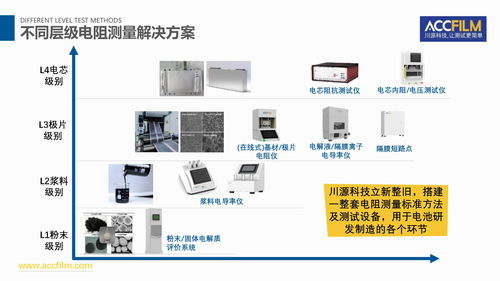
從傳統(tǒng)數(shù)據(jù)中心向以人工智能為核心的智算中心演進,不僅是硬件算力的堆砌,更是一場深刻的網(wǎng)絡技術變革。要打通這一轉型路徑,網(wǎng)絡技術的研發(fā)需在以下幾個關鍵環(huán)節(jié)實現(xiàn)突破與協(xié)同。
一、 互聯(lián)架構:從通用到異構,擁抱超大規(guī)模無損網(wǎng)絡
傳統(tǒng)數(shù)據(jù)中心網(wǎng)絡基于TCP/IP協(xié)議棧,為通用計算設計,存在延遲、丟包和擁塞等問題。而智算中心的核心——大規(guī)模AI集群訓練(如萬卡集群)對網(wǎng)絡提出了近乎嚴苛的要求:超高帶寬、超低延遲、零丟包。因此,技術研發(fā)必須聚焦:
- RDMA(遠程直接內存訪問)技術的深度應用與優(yōu)化:繞過操作系統(tǒng)內核,實現(xiàn)服務器間內存的直接、高速訪問,是降低延遲的關鍵。需要解決RDMA大規(guī)模部署下的流量控制、擁塞管理、與現(xiàn)有基礎設施融合等問題。
- 新型互聯(lián)協(xié)議與交換架構:如InfiniBand,憑借其原生無損特性和低延遲,已成為高端智算網(wǎng)絡的主流選擇。基于以太網(wǎng)的RoCE(RDMA over Converged Ethernet)技術也在快速發(fā)展,旨在將以太網(wǎng)的生態(tài)優(yōu)勢與RDMA的高性能結合,其核心在于通過PFC(優(yōu)先級流控制)、ECN(顯式擁塞通知) 等機制實現(xiàn)“無損以太網(wǎng)”。研發(fā)重點在于提升RoCE的規(guī)模化部署能力和穩(wěn)定性。
- 非阻塞網(wǎng)絡拓撲:采用Clos、Dragonfly+ 等拓撲結構,構建無阻塞、高帶寬、多路徑的網(wǎng)絡平面,以滿足成千上萬個加速卡(GPU/ASIC)間全連接通信的需求。
二、 計算與網(wǎng)絡的協(xié)同設計:解耦與重構
智算中心中,計算(GPU/NPU)與網(wǎng)絡的關系從“連接”變?yōu)椤叭诤稀薄<夹g環(huán)節(jié)包括:
- 片間互聯(lián)與節(jié)點內互聯(lián):在單個服務器節(jié)點內部,多顆加速卡之間通過NVLink、PCIe 等高速互聯(lián)技術形成緊密耦合的計算單元。網(wǎng)絡技術需與這些內部互聯(lián)協(xié)議高效對接,形成統(tǒng)一的內存地址空間和通信域。
- 網(wǎng)算一體與智能網(wǎng)卡(DPU/SmartNIC):將部分網(wǎng)絡、存儲和安全功能從CPU卸載到專用的數(shù)據(jù)處理單元(DPU)或智能網(wǎng)卡上。這不僅能解放CPU資源,更能實現(xiàn)網(wǎng)絡協(xié)議的在網(wǎng)處理、集合通信優(yōu)化(如All-Reduce操作的部分卸載),從而大幅提升整體系統(tǒng)效率。這是研發(fā)的前沿熱點。
三、 網(wǎng)絡智能化與可觀測性:從被動運維到主動調度
智算工作負載(尤其是分布式訓練)動態(tài)多變,網(wǎng)絡必須更加智能。
- AI賦能的網(wǎng)絡自治:利用機器學習模型預測流量模式、實時檢測與規(guī)避擁塞、自動優(yōu)化路由策略,實現(xiàn)網(wǎng)絡的自配置、自修復、自優(yōu)化。
- 端到端的精細化可觀測性:部署細粒度的遙測技術(如INT,帶內網(wǎng)絡遙測),實時采集網(wǎng)絡路徑上的延遲、丟包、隊列深度等數(shù)據(jù),并結合訓練作業(yè)的語義信息(如迭代周期),快速定位性能瓶頸是在計算、存儲還是網(wǎng)絡,實現(xiàn)跨層調優(yōu)。
四、 光互聯(lián)技術:突破帶寬與距離的物理極限
隨著單芯片速率向800G、1.6T發(fā)展,電互聯(lián)在功耗和距離上的瓶頸日益凸顯。光互聯(lián) 技術成為必然選擇:
- CPO(共封裝光學)和NPO(近封裝光學):將光引擎與交換芯片或計算芯片封裝得更近,極大降低接口功耗和尺寸,是未來超高速互聯(lián)的核心方向。
- 高速光模塊與硅光技術:研發(fā)更低功耗、更低成本的800G/1.6T高速光模塊,利用硅光技術實現(xiàn)光電集成的大規(guī)模生產。
五、 軟件定義與自動化:統(tǒng)一編排的基石
硬件變革需要軟件定義來驅動。
- 統(tǒng)一通信庫與編排:優(yōu)化NCCL、OneCCL 等集合通信庫,使其能充分感知底層異構網(wǎng)絡(IB、RoCE)的拓撲和特性,實現(xiàn)最優(yōu)通信算法選擇。
- 云網(wǎng)智一體化的資源調度:通過軟件定義網(wǎng)絡(SDN)和智能編排器,將網(wǎng)絡資源(帶寬、拓撲)與計算資源(GPU)、存儲資源作為一個整體進行統(tǒng)一調度和彈性分配,根據(jù)AI任務的需求動態(tài)生成最優(yōu)資源組合。
而言,從數(shù)據(jù)中心到智算中心的網(wǎng)絡技術打通,是一條從“通用互聯(lián)”走向“智算融合” 的路徑。它要求研發(fā)不再局限于單純的帶寬提升,而是需要圍繞無損傳輸、異構協(xié)同、網(wǎng)算一體、智能運維和光電融合等多個維度進行系統(tǒng)性的創(chuàng)新與整合。只有打通這些環(huán)節(jié),網(wǎng)絡才能從“管道”進化為智能計算的“神經系統(tǒng)”,真正支撐起智算時代的萬千應用。